Performance Best Practice(Ord7)
Ord7
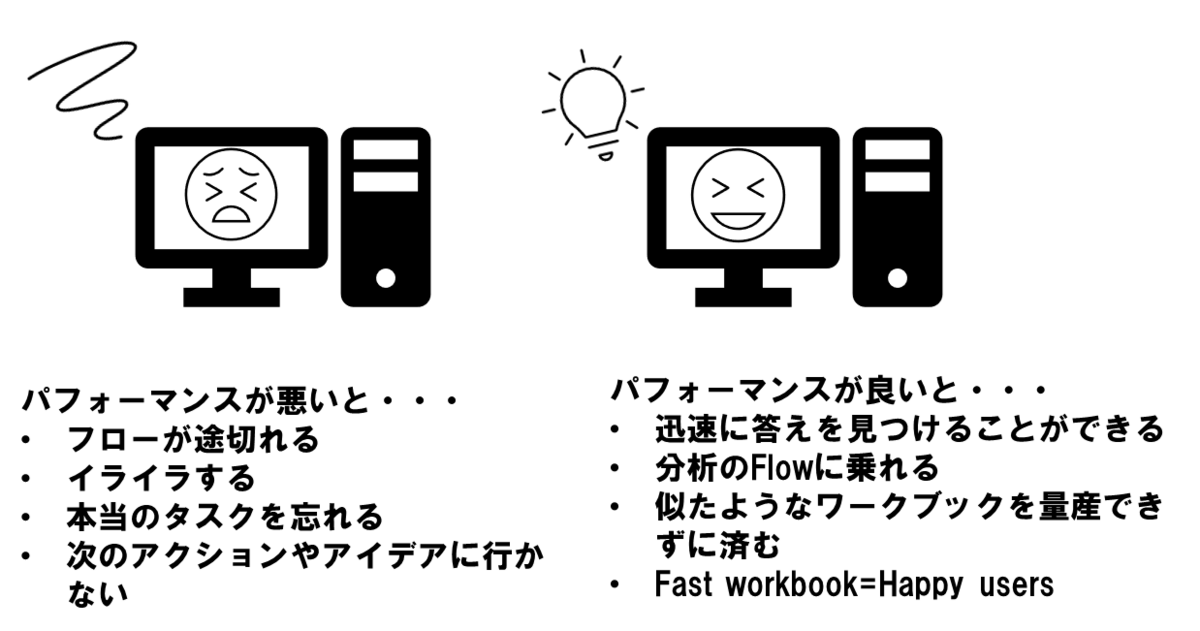
パフォーマンスについて考える!
〇なぜパフォーマンスが大事なのか
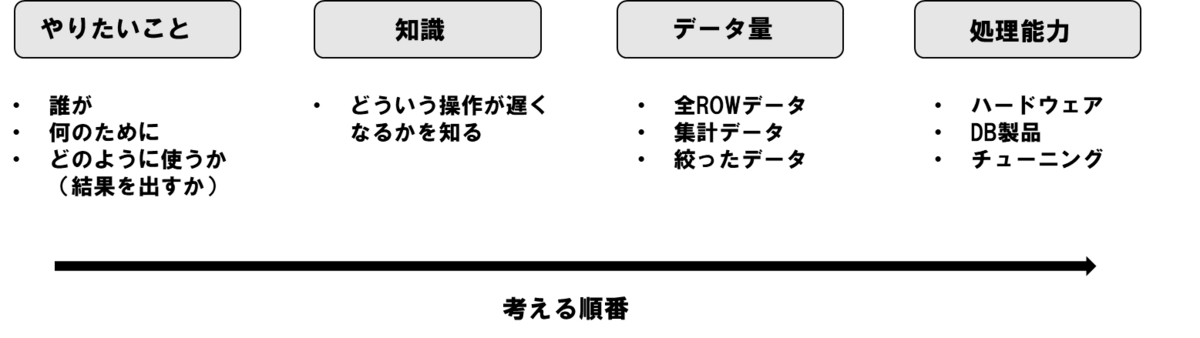
〇パフォーマンスを決める要素
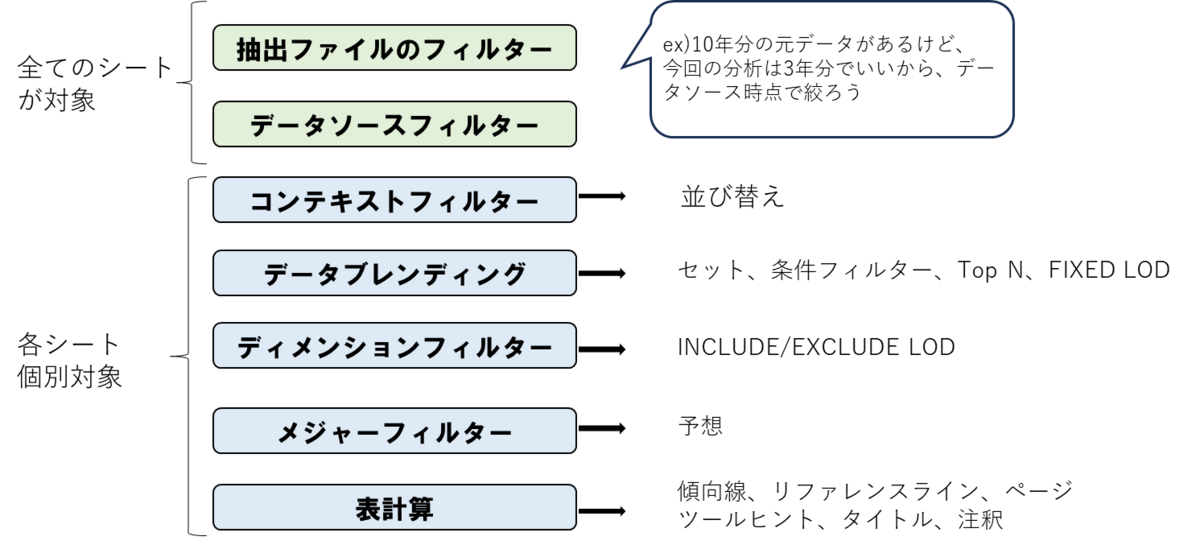
〇誰が何を処理しているかが重要
⇒どこで処理しているかが分かれば、パフォーマンスが悪いときすぐに原因が分かる
ex)データが重い原因がマークの量であるのに、DBを変えても意味がない

用語の確認
- クエリの実行:データベースからデータの抽出・操作をしている
- レンダリング:データを処理または演算することで画像を表示させること
〇ベストプラクティス
- データが遅ければ、タブローで早くなることはない
- DeskTopで遅ければ、Saverで早くなることはない ⇒Saverは基本的に同時に色んな仕事をしているため、難しい
- 入れすぎ注意(シンプルに)
⇒パフォーマンスについて考えているのであれば、Tableauの気持ちを汲み取っていく
〇タブローの気持ちを聞く:パフォーマンス記録
- 何が起こっているのか?何に時間がかかっているのか? ⇒サーバーパフォーマンスビューを確認
- タブロー画面での見方
ヘルプ→設定とパフォーマンス→パフォーマンスの記録を開始→色々操作してみる→パフォーマンスの停止

⇒ログを取得することで、何に時間がかかっているかが分かる
〇データ量とパフォーマンスのジレンマ
データは多ければ多いほどたくさんのことを知ることが出来る
VS
データは多ければ多いほど遅くなる(=Floeに乗れない)
⇒最善のバランスをどう見つけていくかが重要
〇対象データの特徴
レコード数
⇒行数が多いvs集計され行数が少ない
フィルターを使用し、件数を削減
- 抽出フィルター
- データソースフィルター
〇パフォーマンスが悪いときにチェックする項目
1.レコード数:今の環境で扱えるくらいの数か
【対処策】
- 集計し行数を減らす
- フィルターを使用し件数を減らす(抽出フィルター、データソースフィルター) ※Tableauでは普通でメンションフィルターでは件数は減っていないので注意
【The Query Pipeline】
2.リレーショナル・データベース(リレーショナル・データベースが元データの時)
【対処策】
- インデックス
- パーティショニング
【NULL】
- ディメンション項目ではNULLを避ける
- NULLをなくしてインデックス効果を向上
【DB側でテーブルを準備】
- 集計データを事前準備
- Tableauでの複雑な計算フィールドを回避するために、事前にDB側に必要な値をテーブルに持たせておく
【結合】
-
(特殊な事情でなければ)同じデータベースであれば、表の結合が望ましい
-
インデックスを有効利用
-
1本のクエリ ⇒1つのテーブルだったら基本的には結合を使う
【ブレンド】
- レコード数が多く、表の結合に適さない場合
- 集計ビュー
【結合&クロスデータベースの結合】
- ファクト(トランザクション)テーブルとマスタテーブルの結合
【ブレンディング】
- 多対多リレーションシップなどJoinした際に値が合わないデータを結合
〇結合vsブレンディングvsクロスデータベース結合

〇抽出VSライブ接続
⇒抽出、ライブ接続のどちらが速いかはケースバイケース
- データの抽出のパフォーマンスに影響する要因 -行数 -列数(抽出ファイル作成時に影響) -データ濃度(=カーディナリティ。ディメンションメンバーの数) ⇒細かいかどうか
〇計算
1.行レベル計算と集計計算
- データベース側で計算処理
- 行レベル計算はスケーラビリティが高い -DBチューニング施策が効果を出しやすい
2.行レベル計算と集計計算を分割
- 行レベル計算を1つの計算フィールドに
- 集計計算を2つ目の計算フィールドに
3.表計算
- クエリ結果を受け取り、Tableauが計算処理
- 計算フィールドよりもTableauの計算負荷が高い
〇計算フィールドVSネイティブ機能
- ネイティブ機能は計算フィールドより速いことが多い -ディメンションメンバーのグルーピング⇒グループが有効
- ディメンションメンバーの変更 ⇒別名の編集が有効
- メジャー値のカテゴリ化 -ビンの有効
〇計算フィールド
- データ型はパフォーマンスへの影響が大きい -整数はプールより速い -整数・プールは文字よりも速い
⇒整数>プール>文字列の順で速い
- 特にロジック計算はIF文ではなく、ブーリアン(プール値)を使用すると速い
〇日付の計算
日付型への変換
- 文字型への変換は非効率
- 数値型とDATEADD()の組み合わせ
- 文字型を右クリックして日付型に直接変えればよい
- 8桁の数字は基本的に日付型に変更できるが、もしNULL表示になった場合は「DATEPARSE」関数を使用
日付関数
- NOW():システムタイムスタンプ
- TODAT():システムスタンプ
〇フィルター(日付)
- 不連続フィルターは遅い -TableauはDBにクエリを発行し、すべてのディメンションを取得しにくい
- 範囲(連続)フィルターは速い -頭とお尻だけあればいいから、範囲の中に何があるかは関係ないから速い -大量の不連続値を取り込むと速い
- 保持・除外フィルターは遅い
☆日付も同じ
- 相対日付はさらに速い
〇フィルター(クリック)
- 項目が表示されたクイックフィルターは遅い (ドロップダウン、数値、範囲日付) ⇒表示する項目をすべて取得(探す)必要があるため
- 項目がデータに依存しないクイックフィルターは速い (カスタムリスト、ワイルドカード、相対日付) ⇒フィルターのために表示する項目を探す必要がないため
〇 ダッシュボード上のクリックフィルター
- 大量のクイックフィルターは遅い原因 ⇒たくさんのディメンションリストを取得しなければならない
【対処策】
- 異なるディメンションレベルで複数シートを作る ⇒フィルターアクションを活用する -クイックフィルターでリストから選択ではなく、シート上で直接選択できるようにする
- パラメーターを活用する
〇ダッシュボード
- シートやクイックフィルターを少なくする -1シートにつき少なくとも1クエリ
- タブを非表示にする(特にSarverの場合) -タブの表示されているビューはすべてプロセスが走る ⇒タブを非表示にするためにワークブックの構造を把握するプロセス
- フィルターアクション「すべて値を除外」を活用
- ダッシュボードサイズは固定する
シートを作るとき・・・
⇒本当に必要なものだけを取得、表示する
(マークカードに不要な詳細を入れない)
⇒不要な地理的役割は設定しない
〇Tableauの向き/不向き
